

Chapitre 3. Retour sur le codage
Nous avions donné quelques rudiments de codage dans la section 3. Nous y revenons ici plus en détail en illustrant les différentes catégories d’information que nous pouvons coder :
• bien évidemment les caractères, mais dans le monde d’aujourd’hui, ce sont les caractères de toutes les langues du monde qu’il faut pouvoir coder, c’est aussi notre capacité à produire des documents multilingues que les techniques de codage doivent prendre en charge,
• les nombres de toute nature et de toute précision. Certains modes de codage des nombres seront plus adaptés à la réduction de l’espace de stockage occupé et à la facilité de manipulation pour les calculs,
• le codage des couleurs sera un autre exemple.
Remarque :
Nous ne sommes pas obligés, pour suivre l'ensemble de la section, d'entrer dans le détail de ce chapitre sur le codage mais il est intéressant de voir combien les fichiers peuvent être volumineux.
3.1. Tour de Babel du codage des caractères
Jusque dans les années 80, chaque constructeur d'ordinateurs utilisait son propre codage.
Exemple :
Control Data utilisait le « Display Code », codage sur 6 bits seulement.
IBM avait, de son côté, créé le code EBCDIC (Extended Binary Coded Decimal Interchange Code), mode de codage des caractères sur 8 bits créé par IBM.
Cette multiplicité de codes entraînait des incompatibilités multiples entre les différents ordinateurs.
Complément : Le code ASCII
Le code ASCII (American Standard Code for Information Interchange) est un code à 7 bits permettant de représenter tous les caractères anglo-saxons utilisés par un certain nombre de constructeurs d'ordinateurs. C'est également la variante américaine de la norme de codage de caractères ISO/CEI 646.
Les codes 0 à 31 ne sont pas des caractères visibles. On les appelle caractères de contrôle car ils permettent de faire des actions telles que :
Les codes 65 à 90 représentent les majuscules. Les codes 97 à 122 représentent les minuscules. |
Représentation graphique | Représentation binaire | |
Display code (Control Data) | A | 000 001 |
ASCII 7 bits | A | 100 0001 |
EBCDIC (IBM) | A | 1100 0001 |
Tous ces codes ont subi des variations au cours du temps mais aucun d’entre eux ne permettait de représenter des caractères latins, grecs, cyrilliques, etc.
Dans les années 1990, l'ISO a re-normalisé et étendu le code ASCII et a créé la norme ISO 8859 :
Le codage se fait systématiquement sur 8 bits.
• Les 128 premiers caractères sont ceux d'ASCII,
• Les 128 suivants sont spécifiques de la langue.
16 versions ont été créées pour toutes les langues européennes, l’hébreu, le cyrillique, l’arabe et quelques autres.
Complément : Les 16 versions de la norme de codage ISO 8859
ISO 8859-1 (latin-1 ou européen occidental) | C'est la partie la plus largement utilisée de ISO 8859, couvrant la plupart des langues européennes occidentales : l'allemand, l'anglais, le basque, le catalan, le danois, l'écossais, l'espagnol, le féringien, le finnois (partiellement), le français (partiellement), l'islandais, l'irlandais, l'italien, le néerlandais (partiellement), le norvégien, le portugais, le rhéto-roman et le suédois, certaines langues européennes sud-orientales (l'albanais), ainsi que des langues africaines (l'afrikaans et le swahili). Le symbole de l'euro et la capitale Ÿ, qui manquaient, sont dans la version révisée ISO 8859-15 (latin-9). Le jeu de caractères correspondant ISO-8859-1, approuvé par l'IANA, est le codage par défaut des anciens documents HTML ou des documents transmis par messages MIME, tels que les réponses HTTP quand le type de média du document est « text » (par exemple les documents « text/html »). |
ISO 8859-2 (latin-2 ou européen central) | Langues d'Europe centrale ou de l'Est basées sur un alphabet romain (le bosniaque, le croate, le polonais, le tchèque, le slovaque, le slovène et le hongrois). |
ISO 8859-3 (latin-3 ou européen du Sud) | Le turc, le maltais, et l'espéranto ; supplanté par ISO 8859-9 pour le turc et par Unicode pour l'espéranto. |
ISO 8859-4 (latin-4 ou européen du Nord) | L'estonien, le letton, le lituanien, le groenlandais et le sami. |
ISO 8859-5 (cyrillique) | La plupart des langues slaves utilisant un alphabet cyrillique, y compris le biélorusse, le bulgare, le macédonien, le russe, le serbe et l'ukrainien (partiellement). |
ISO 8859-6 (arabe) | Couvre les caractères les plus courants de l'arabe. Nécessite un moteur de rendu qui prend en charge l'affichage bidirectionnel et l'analyse contextuelle. |
ISO 8859-7 (grec) | La langue grecque moderne (orthographe monotonique). |
ISO 8859-8 (hébreu) | L'alphabet hébraïque moderne tel qu'il est utilisé en Israël. |
ISO 8859-9 (latin-5 ou turc) | Proche de l'ISO 8859-1, où les lettres islandaises peu utilisées sont remplacées par des lettres turques. Il est aussi utilisé pour le kurde. |
ISO 8859-10 (latin-6 ou nordique) | Réarrangement du latin-4. Considéré plus utile pour les langues nordiques. Les langues baltes utilisent plus souvent le latin-4. |
ISO 8859-11 (thaï) | Contient la plupart des glyphes requis pour la langue thaï. |
ISO 8859-12 | Était supposé couvrir l'alphabet devanāgarī, mais ce projet a été abandonné en 1997. ISCII et Unicode/ISO/CEI 10646 couvrent le devanāgarī. |
ISO 8859-13 (latin-7 ou balte) | Ajoute quelques caractères supplémentaires pour les langues baltes qui manquaient en latin-4 et latin-6. |
ISO 8859-14 (latin-8 ou celtique) | Couvre des langues celtiques telles que l'irlandais (orthographe traditionnelle), le gaélique écossais, le mannois (langue disparue) et le breton (certaines anciennes orthographes). |
ISO 8859-15 (latin-9) | Révision de 8859-1 qui abandonne quelques symboles peu utilisés, les remplaçant avec le symbole de l'euro € et les lettres Š, š, Ž, ž, Œ, œ, et Ÿ, ce qui complète la couverture du français, du finnois et de l'estonien. |
ISO 8859-16 (latin-10 ou européen du Sud-est) | Prévu pour l'albanais, le croate, le hongrois, l'italien, le polonais, le roumain et le slovène, mais aussi le finnois, le français, l'allemand et l'irlandais (en nouvelle orthographe). Cette police mise plus sur les lettres que les symboles. Le signe de monnaie est remplacé par le symbole de l'Euro. |
Les normes de codages doivent évoluer car le langage évolue et de nouveaux besoins apparaissent.
Exemple :
Le symbole € et les Œ, œ et Ÿ qui manquaient pour l'écriture du français ont été ajoutés à la norme 8859-15 qui constitue une révision de l'ISO latin 1 (8859-1).
Comme le nombre de position sur un octet est limité à 256, un certain nombre de symboles peu utilisés ont été abandonnés au profit de quelques nouveaux
Complément : De l'ISO latin-1 à l'ISO latin-15 : Différences ISO 8859-15 --- ISO 8859-1
Position | 0*A4 | 0*A6 | 0*A8 | 0*B4 | 0*B8 | 0*BC | 0*BD | 0*BE |
8859-1 | ¤ | ¦ | ¨ | ´ | ¸ | ¼ | ½ | ¾ |
8859-15 | € | Š | š | Ž | ž | Œ | œ | Ÿ |
De son coté, Windows utilise le codage Windows-1252 Identique à ISO 8859-1 sauf dans la plage 80-9F.
Conclusion
Mais alors, comment faire pour écrire un texte mixte français – grec ?
D'une manière générale comment encoder des documents multilingues ?
Comment prendre en compte les langues asiatiques ?
Comment prendre en compte le sens de l'écriture ?
3.2. Codage universel des caractères
A partir de 1993 s'est constitué le consortium Unicode afin d’apporter des réponses à ces questions et essayer de régler définitivement ce problème de la représentation des textes sur un ordinateur. Un jeu universel des caractères a ainsi été défini.
Au cours des années 1990, le consortium Unicode et le comité technique mixte ISO/CEI JTC 1, Technologies de l'information, sous-comité SC 2, Jeux de caractères codés ont coordonné leurs efforts. Le jeu universel de caractères codés sur plusieurs octets, défini par la norme internationale ISO 10646 et par le standard Unicode sont identiques. Par contre, la norme ISO ne précise ni les règles de composition de caractères, ni les propriétés sémantiques des caractères, ce que fait Unicode. La norme ISO 10646 existe en anglais et en français.
Complément :
L'ensemble du jeu de caractères ainsi défini doit être considéré comme formé de 128 groupes de 256 plans. Chaque plan est formé de 256 rangées de caractères, chaque rangée contenant 256 cellules. Chaque caractère du jeu complet de caractères codés doit être représenté par une suite de quatre octets qui est appelée point de code.
Octet de groupe (octet G) | Octet de plan ( octet P) | Octet de rangée (octet R) | Octet de cellule (octet C) |
Cet espace de codage est immense. Le jeu de caractère prévoit des zones spécifiques pour les usages privés ainsi que de multiples possibilités d’extensions.
Le plan 00 du groupe 00 constitue le plan multilingue de base (PMB). Ce PMB peut être utilisé comme jeu de caractères codés à deux octets (l’octet de rangée et l’octet de cellule, sachant implicitement que l’octet de groupe et l’octet de plan ont la valeur hexadécimale 00). Pour cette raison le PMB sera alors appelé UCS-2 (Universal Character Set 2). Ce plan nous intéresse particulièrement car il permettra de répondre à l’essentiel des besoins.
Rangée | code |
00 à 02 | Latin de base, Supplément Latin-1, Latin étendu A, Latin étendu B, Alphabet phonétique international |
03 à 05 | Grec et copte, Cyrillique, Arménien Hébreu |
06 | Arabe |
07 | Syriaque, Thâna |
09 à 12 | Dévanâgarî, Bengali, Gourmoukhî, Tamoul, Thaï, Tibétain, Birman, Éthiopien.... |
1E | Latin étendu additionnel |
1F | Grec étendu |
20 à 22 | Ponctuation générale, Exposants et indices, Symb. Monétaires, Formes numériques, Flèches, Opérateurs mathématiques |
... | ... |
28 | Combinaisons Braille |
2F | Clés chinoises (K'ang-hsi ou Kangxi) |
.etc. |
Chaque caractère graphique est identifié par un nom unique normalisé. Par contre, le glyphe représentant le caractère n'est pas normalisé par l'ISO 10646. Les symboles graphiques sont considérés comme des représentations visuelles types des caractères, représentations qui vont dépendre de la fonte utilisée.
Point de code hexadécimal (normalisé) | Nom (normalisé) | Glyphe (non normalisé) |
0041 | LETTRE MAJUSCULE LATINE A | A |
00C7 | LETTRE MAJUSCULE C CEDILLE | ç |
03B1 | LETTRE MINUSCULE GRECQUE ALPHA | |
Ce jeu de caractère et l’ensemble des mécanismes associés permettent :
• de traiter des textes multilingues,
• de traiter toutes les écritures quels que soient les symboles et quel que soit le sens d'écriture.
Compatibilité :
Le point de code d'Unicode est compatible
Avec l'ASCII sur les 128 premiers index,
Avec ISO Latin-1 sur les 128 suivants.
Cela rend les chaînes Unicode manipulables par les langages standards de l'Internet.
Mise en oeuvre :
En pratique, le jeu de caractères universel, sous sa forme canonique à 4 octets constitue un référentiel à partir duquel plusieurs encodages différents seront définis en fonction des besoins :
UTF-8, qui est l’encodage par défaut de XML. UTF-8 peut être considéré aujourd’hui comme l’encodage standard de l’Internet. UTF signifie : « UCS transformation format ». UTF-8 permet la représentation de tous les caractères du jeu universel. C’est le plus utilisé, c’est un encodage de taille variable, chaque caractère est codé sur un ensemble variant de 1 à 6 octets.
UTF-16 est un encodage fixe sur 2 octets.
UTF-32 est un encodage fixe sur 4 octets. C’est le seul pour lequel le point de code correspond à la représentation en mémoire. C’est le plus gourmand en ressources.
UTF-8 a été inventé pour permettre à la fois :
La représentation de tous les caractères existant dans le jeu universel,
La compatibilité avec l’ASCII, ce qui offre le double avantage d’un gain en performance (le codage des caractères ASCII reste toujours sur un seul octet) et la compatibilité avec les textes existants.
Caractère | Code point | Encodage UTF8 |
A | 41 | 01000001 |
é | 00E9 | 11000011 10101001 |
€ | 20AC | 11100010 10000010 10101100 |
3.3. Où spécifier le codage ?
La façon de spécifier le codage que l’on veut utiliser va dépendre du logiciel.
Dans Word nous pouvons procéder ainsi :
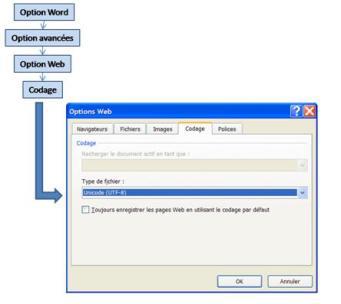
Nous pouvons ajouter qu’en l’absence de spécification du codage, Word s’appuiera sur un codage par défaut de Windows qui est un codage non normalisé.
Dans les fichiers XML dont nous parlerons un peut plus loin, nous trouvons en tout début de chaque fichier XML :
<?xml version="1.0" encoding="UTF-8"?>
3.4. Codage des nombres
Pour pouvoir représenter des nombres, on attribue des valeurs aux positionnements des bits.
Complément : Cas des nombres entiers – représentation dite binaire
On décompose l'entier en puissances de 2 et on attribue 0 ou 1 à chaque puissance
183 = 1x128 + 0x64 + 1x32 + 1x16 + 0x8 + 1x4 + 1x2 + 1x1
183 pourra être représenté par 10110111 ou par 11101101 en fonction du sens qui sera utilisé pour lire cette petite séquence de bits. Dans le premier cas, on a mis les bits de poids fort (ceux affectés aux puissances supérieures de 2) à gauche, Dans l'autre, on a mis les bits de poids fort à droite : • La première approche est appelé gros-boutiste (Big Endian en anglais), elle est utilisée sur les processeurs Intel (sous Windows par exemple), • La seconde approche est appelé petit-boutiste (Little Endian en anglais), elle est utilisée par les processeurs Motorola (sous MacOS par exemple) |
Selon la grandeur du nombre entier, il faut plus ou moins de bits pour le représenter :
avec 8 bits, on représente des nombres entiers positifs de 0 à 255
avec 16 bits on ira jusqu'à 65536
avec 32 bits jusqu'à 4 294 967 296
avec 64 bits jusqu'à 1 844 674 073 709 551 616
En fait les valeurs sont plus faibles car il faut réserver un bit pour le signe.
Cas des nombres entiers – représentation dite codée
On peut utiliser une autre méthode très simple pour représenter un nombre entier :
Le nombre 183 peut être représenté en codant successivement :
le caractère « 1 » du codage universel des caractères (identique ici à l’ISO latin-1) (0110001)
le caractère « 8 » de ce même codage (0111000)
le caractère « 3 » de ce même codage (0110010)
Cette représentation présente un avantage et un inconvénient :
l’avantage est que cette valeur sera immédiatement lisible sur n’importe quel éditeur de texte qui interprète les caractères ;
l’inconvénient est que pour représenter « 183 » sous une forme codée, il faut 3 octets, soit 24 bits alors qu’il ne faut que 8 bits pour représenter ce nombre sous une forme binaire ; cet inconvénient sera marginal dans de nombreux cas mais sera problématique dès que l’on à affaire à des grands volumes de données ; il sera plus rapide et moins coûteux de stocker 1 Go sous une forme binaire que 3 Go sous une forme codée.
Nous pourrons donc dire que le nombre entier positif 183 peut être représenté par :
la séquence de bits 10110111 (mode binaire),
la séquence de bits 0110001 0111000 0110010 (mode codé)
Ces séquences de bits ne pourront être interprétées correctement que si nous disposons par ailleurs d’une information précisant le mode de représentation du nombre, cette information constituant elle-même une partie de l’Information de représentation au sens du modèle OAIS.
Codage des nombres rationnels et plus généralement des nombres réels :
En informatique, on parlera aussi de nombre en virgule flottante.
En théorie, un nombre réel est formé de 4 éléments :
la mantisse (nombre entier positif),
le signe du nombre réel,
l’exposant,
le signe de l’exposant.
Là encore, nous pouvons définir une représentation dite binaire et une représentation dite codée.
La représentation codée suivra les mêmes règles que pour les nombres entiers.
Le nombre -523,12 peut être codé avec 7 caractères : le signe « - », le séparateur « virgule » entre la partie entière et la partie fractionnaire et les chiffres nécessaires à la composition du nombre. Le nombre 1,6327-4 pourra être en pratique codé sous la forme +1,6327E-04 (le caractère « E » vient préciser que le nombre qui suit est un exposant. 11 octets seront nécessaires dans ce cas. |
La représentation binaire des nombres réels sera plus souvent utilisée pour effectuer des calculs. Un artifice technique de normalisation entre la mantisse et l’exposant permet d’avoir un exposant systématiquement positif et par conséquent, de ne pas avoir à stocker le signe de l’exposant.
En général, on utilise, en fonction des ordinateurs et des besoins en précision, des représentations d’une longueur de 32, 64 ou parfois 128 bits. Cela signifie que la longueur cumulée de la mantisse, de l’exposant et du signe doivent correspondre à ces longueurs.
Là encore, il y a un certain nombre de conventions différentes en fonction des systèmes d’exploitation et des constructeurs. L’une de ces conventions est standardisée et nous en recommandons l’utilisation :
Il s’agit du standard 754-2008 IEEE Standard for Floating-Point Arithmetic.
Selon ce standard, un nombre flottant simple précision est stocké sur 32 bits : 1 bit de signe, 8 bits pour l'exposant et 23 bits pour la mantisse.
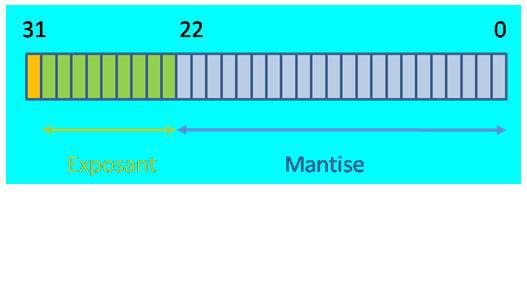
Un nombre flottant double précision est stocké sur 64 bits :1 bit de signe, 11 bit pour l’exposant et 52 bits pour la mantisse.
3.5. Autres codages
Pour le codage des couleurs, il s’agit là encore de définir une convention qui permettra de définir la couleur d’un pixel dans une image ou d’un caractère dans un texte, etc. Le pixel est la plus petite unité adressable de l'écran.
Plusieurs possibilités existent :
le codage d’une palette de 256 couleurs, dans ce cas, un octet suffira pour définir la couleur,
le codage sur 3 octets (24 bits) : 8 bits sont consacrés à la teinte primaire rouge, 8 bits sont consacrés à la teinte primaire vert, 8 bits sont consacrés à la teinte primaire bleu,
Le codage sur 4 octets (32 bits) : 24 bits sont utilisés comme pour le codage précédent, le dernier octet est soit inutilisé, soit utilisé à coder par exemple une information de transparence.
Il existe des codages spécifiques pour le son, d’autres pour la vidéo vue comme un ensemble d’images.




