

6.7. La reconnaissance optique des caractères
Le procédé s'appelle en Français Reconnaissance optique des caractères (ROC) et en Anglais Optical Characters Recognisation (OCR). Il consiste à reconnaître les textes dans l'image d'une page numérisée.
Les textes manuscrits ne sont pas aptes à la Reconnaissance Optique des Caractères, pour une cause évidente de complexité. Généralement, ce sont des communautés participatives de paléographes qui retranscrivent les manuscrits.
Par contre les textes dactylographiés, en caractères d'imprimerie, ou en écriture bâton très soignée sont aptes à la reconnaissance optique des caractères.
Le chapitre qui suit s'applique autant à ces documents texte qu'aux imprimés comprenant des similigravures et autres images dont nous parlerons au chapitre 9
Comment fonctionne une ROC ?
L'algorithme fonctionne seul, dès qu'il a été mis en route par l'opérateur. Il traite des pages entières. Les phases successives sont :
• Le redressement de l'image de la page pour aligner les lignes sur la grille d'expertise.
• La décomposition de la page en éléments contenant du texte ou des images.
• La bitonalisation du texte pour la reconnaissance.
• L'établissement de la correspondance entre les pixels de chacun des caractères avec une matrice décrivant le caractère type.
• La comparaison des mots formés avec un dictionnaire, permettant d'intégrer certains « suspects » pour reformer un mot.
Ensuite, le texte est soit exporté vers une application indépendante (exemple ABBYY fine reader), soit directement disposé en couche sous-jacente à l'image dans le fichier PDF représentant l'archive (Adobe Acrobat®). C'est cette deuxième solution qui intéressera l'archiviste, qui veut montrer le document dans son aspect d'origine.
L'option vectorisation des caractères
Il existe dans Adobe Acrobat® une option qui permet de transformer le texte pixellisé en texte vectoriel (mode clearscan).Les contours des caractères sont dessinés en langage Postscript® emprunté à Illustrator®. Ils deviennent ainsi très nets rendant la lecture aisée et la réimpression très nette. La taille du fichier diminue drastiquement. Ce principe est applicable aux documents :
• Au mode bitonal (fond blanc)
• Au mode couleur ou niveaux de gris. Dans ce cas le fond situé sous les textes est flouté.
Les caractères vectorisés reprennent la couleur des caractères originaux. Les images, signatures, tampons sont préservés dans l'aspect d'origine et à leur place. Les tonalités du papier ancien sont conservées, mais le détail du grain disparaît.
L'aspect du papier n'étant pas entièrement préservé, l'archiviste peut vouloir ne pas activer cette option pour des documents anciens ayant une certaine esthétique, il conservera alors l'aspect original du document avec le texte indexé sous-jacent, mais pour une taille de fichier plus grande.
Ci-dessous, l'exemple qui a été choisi est dans les plus critiques pour une ROC : c'est un tirage de duplicateur à alcool, de couleur violette , mais avec des caractères bien formés.
A quoi sert de faire la ROC d'une archive ?
La première utilité est l'indexation du document, c'est à dire que l'on peut faire des recherches d'un mot contenu dans ce document, directement à partir de la fenêtre de recherche d'un lecteur de document PDF. Mais aussi, ce document peut être localisé dans un répertoire ou un serveur à partir d'un mot qu'il contient. Très aisé si par exemple on recherche un nom propre !
La seconde utilité est la récupération du texte contenu dans le document pour en faire un texte de citation, de travail etc. Ce texte intégré sert aussi à faire la lecture par la voix de synthèse destinée aux malvoyants.
Les logiciels Adobe permettent de sortir le texte par le copier – coller, page par page ou d'exporter tout le document en un seul fichier vers une application de traitement de texte, avec ou sans mise en page.
Exemple de fenêtre de choix de ROC, avec trois options : « Image indexable » pour la page redressée après ROC, « Image indexable exacte » pour une page non redressée, dans ce cas, la sélection de texte sous-jacent sera approximative ; et «clearscan » s'applique pour un texte vectorisé et une page redressée. | 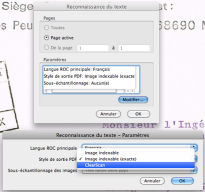 |
Aspect du texte vectorisé. Les caractères ont gardé leur couleur, et même les fautes de frappe sont reproduites comme sur l'original (h de Geishouse) ; le fond est légèrement violet comme l'original. |  |
Comment faire une bonne ROC ?
La reconnaissance optique des caractères fonctionne à partir d'une bitonalisation de la page par le convertisseur. On comprendra aisément que plus la résolution est élevée lors de la numérisation, plus la reconnaissance sera fidèle. Lorsque la résolution atteint 600dpi, pour des caractères de 8-12 points la reconnaissance est au maximum de sa performance. En-dessous de 300dpi , la performance est réduite, surtout si le corps de caractère est en-dessous de 10 points. A ce moment apparaissent les erreurs de reconnaissances, surtout pour les caractères accentués.
Mais alors, pour avoir une ROC fidèle, il va falloir diffuser des fichiers lourds ?
Non car il existe deux solutions :
- après avoir pratiqué l a ROC, on peut choisir dans Acrobat de réduire la taille du fichier par une réduction du nombre de pixels ou par une compression Jpeg plus importante.
- Au moment de pratiquer la ROC, choisir l'option de vectorisation des caractères. Ceci est très adapté aux documents modernes en mode bitonal, mais aussi aux documents anciens et se traduit par un flou du papier pour les documents en tons continus.
Les options de correction
On peut faire la chasse aux mots mal reconnus dans l'application même. Le logiciel présente alors en surbrillance tous les mots ne correspondant pas au dictionnaire, et on peut en refaire la saisie dans une fenêtre dédiée. Si l'on veut être très sélectif, et gagner du temps, cette correction peut être limitée aux noms propres et/ou caractéristiques au document, et elle sera rapide si on sait les localiser.
Testez les fonctions de recherche textuelle et de copie du texte dans la galerie « 6.7 reconnaissance de texte »,
Lors de la copie du texte depuis l'image en PDF, les endroits où la reconnaissance a eu des difficultés sont marqués par des « ? », on peut aussi trouver des mots décomposés en syllabes suite à des espaces importants de la typographie originale du document. A la fin de chaque ligne de l'original, il y a une fin de paragraphe, il faut donc rattacher les paragraphes pour refaire un texte formatable.
Lors de l'export du texte et s'il est justifié à droite, les retours chariot en fin de ligne sont automatiquement supprimés. Le saut de paragraphe se fait dans ce texte si la ligne du document original n'était pas pleine.




