

Chapitre 3. Le modèle d'information
Ce modèle d'information constitue l'une des grandes originalités de la norme OAIS. Il nous fait réellement percevoir toutes les conséquences et toute la spécificité qui sont induites par la nature même du document sous forme numérique.
3.1. Éléments de modélisation UML
Le modèle d’information de l’OAIS s'appuie sur le formalisme UML (Unified Modeling Language) de représentation des objets du domaine et plus spécifiquement sur ce qu'on appelle les diagrammes de classe.
Une classe décrit le comportement et le type d'un ensemble d'objets partageant des propriétés. Une classe est un concept abstrait représentant des objets concrets. Ces objets concrets sont appelés des instances de la classe. Pour désigner le concept d’automobile, on parlera donc de la « classe automobile » ou encore de l'« objet automobile ». L'« objet automobile blanche » constituera une sous-classe de la précédente et héritera de ses propriétés. L’automobile blanche qui est réellement dans votre garage sera une instance de cette sous-classe.
Nous présentons ci-après, les principaux éléments de ce formalisme que nous utiliserons :

On distinguera 3 catégories de relation :
• les associations matérialisées comme ci-dessus par un trait simple entre deux objets. On pourra, sous forme de texte, expliciter la nature de cette association,
• la spécialisation présentée ci-après,
• la composition présentée ci-après.
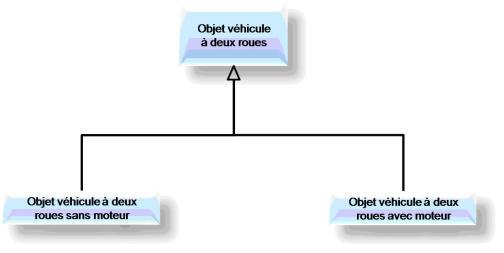
Un objet (une classe) peut être spécialisé en plusieurs objets différents (sous-classes) qui possèdent toutes les propriétés de l'objet « père » auxquelles s'ajoutent des propriétés supplémentaires.
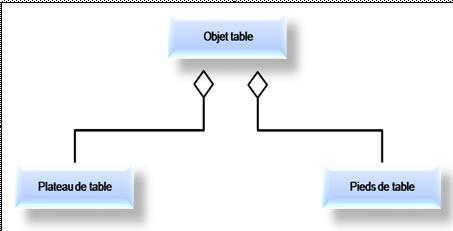
Légende :
Une classe peut être composée de plusieurs sous-classes
Enfin, le dernier élément à connaître concerne ce qu'on appelle la cardinalité :
Légende : Ces règles de cardinalité permettent de définir le caractère optionnel ou obligatoire d’une relation, ainsi que son caractère unique ou multiple | 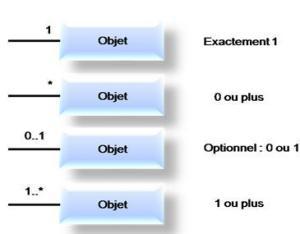 Cardinalité |
3.2. L'Information de représentation
Nous abordons ici le concept fondamental d’Information de représentation, concept que chacun peut pressentir mais qui est ici formalisé clairement.
Nous allons commencer par analyser un exemple.
Exemple :
Supposons que nous ayons à conserver l’information contenue dans un objet numérique tout simple, un document numérique qui se présente sous la forme d’un unique fichier. Cette information qui constitue l’objectif essentiel de la pérennisation sera représentée sous la forme d’un objet appelé « Contenu d’information ».
Notre document se présente sous la forme d’une séquence de bits

Nous pourrions penser qu'il suffit de connaître le format de notre fichier pour accéder à son contenu.
Légende : En pratique, il existe aujourd’hui beaucoup plus de mille formats de fichier, chacun de ces formats pouvant exister en de multiples versions. Certains disparaissent, de nouveaux sont inventés. |  Mais combien de formats de fichiers ? |
Dans notre exemple, nous pouvons ajouter que notre fichier contient des caractères codés conformément à la norme ISO 646 (identique à ce qu’on appelle aussi le codage ASCII). Cette norme définit le codage des lettres de l’alphabet non accentuées, des chiffres et de quelques caractères spéciaux. Pour que nous puissions dans l’avenir lire ce texte, il convient donc d’avoir la certitude que cette norme de codage soit préservée quelque part, ou alors de prévoir d’en assurer la conservation dans l’Archive.
Il est possible d’examiner le contenu de notre fichier avec un simple éditeur de texte qui transforme chaque octet du fichier en une représentation graphique correspondant au caractère codé dans cet octet.
Légende : Nous pouvons visualiser le début de notre fichier avec le bloc-notes, mais nous sommes loin d’en percevoir le sens |  Premier examen de notre fichier avec le bloc-notes |
Ajoutons alors une information nouvelle consistant à préciser que notre fichier est constitué d’une répétition de séquences de longueur fixe égale à 187 octets. Chaque séquence se termine par le caractère « retour chariot » qui signifie qu’il faut passer à la ligne suivante. Toutes ces séquences sont structurées de manière identique et contiennent une succession de champs d’information d’une longueur définie, à savoir :
• 3 nombres entiers codés chacun sur 6 octets
• une séquence de 24 octets avec un codage interne spécifique,
• 3 nombres décimaux d’une longueur de 10 octets chacun,
• etc.
Muni de ces informations, nous pouvons regarder notre fichier avec un éditeur comme textedit qui prend en compte les sauts de ligne. En effet, sur les fichiers de texte, l'information "saut de ligne" présente une difficulté en ce sens qu'elle n'est pas codée de la même façon par tous les systèmes d'exploitation :
• sous Windows, le saut de ligne est codé sur deux caractères (le caractère "Carriage return" + le caractère "line feed",
• sous Linux, un seul de ces deux caractères suffit à déclencher un saut de ligne,
• si nous lisons, avec le bloc note de Windows, un fichier texte créé par un autre système, les sauts de ligne ne seront pas interprétés,
• par contre, ils le seront si nous utilisons un éditeur de texte compatible avec les deux systèmes.
Légende : Cette représentation nous parait déjà plus claire mais il nous manque encore des informations capitales, à savoir la signification de chacun des champs |  Visualisation du fichier prenant en compte sa structure répétitive |
Il est donc nécessaire de définir, un par un et de façon exhaustive, la signification de chacun des champs continus dans la structure répétitive.

Nous voyons apparaître, au travers de cet exemple, une première équation fondamentale :
1. si nous voulons pérenniser l'information contenue dans un objet numérique, information qui sera modélisée par un objet « Contenu d’information », il n'est pas suffisant de conserver cet objet ;
2. il est indispensable de conserver avec cet objet, un ensemble d'informations, appelées « Information de représentation » qui nous permettront de passer des bits constituant l'objet numérique au contenu informationnel de cet objet.

Cette équation se traduit par le diagramme UML suivant :
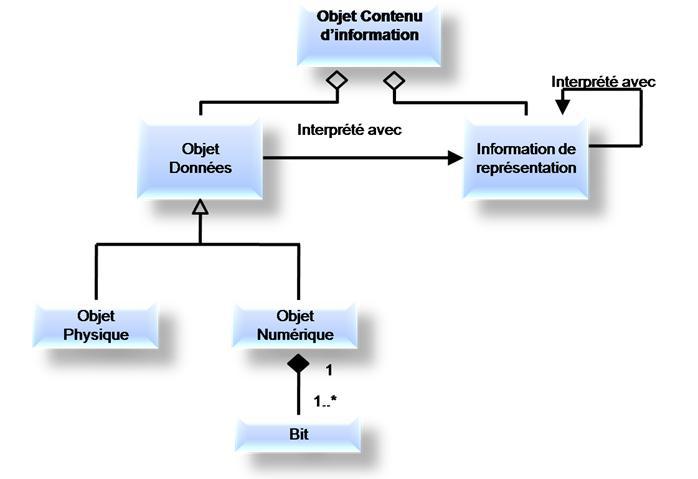
Ce diagramme appelle les commentaires suivants :
• L’Information de représentation étant basée sur des éléments existant également sous forme numérique (par exemple les tables de codage des caractères alphabétiques), elle est elle-même un objet numérique contenant de l’information à préserver, elle doit donc disposer de sa propre Information de représentation. C’est cela qu’exprime la flèche qui sort puis rentre dans le rectangle « Information de représentation »,
• L’objet Données peut aussi bien être numérique que physique (par exemple un ouvrage papier). Dans ce module de cours, nous nous intéresserons essentiellement aux documents numériques, mais le modèle OAIS reste valide pour les documents non numériques. C’est un point important car dans les années à venir, la plupart des services d’archives auront à gérer en même temps des documents non numériques et des documents numériques.
L'Information de représentation doit être en quelque sorte garante de l'intelligibilité de l'information que l'on veut conserver. Cette préoccupation n'est pas nouvelle. Lorsque l’archiviste constitue un dossier, il veille à ce que ce dossier soit cohérent et complet. Cette préoccupation prend cependant ici un caractère essentiel et systématique, lié aux multiples risques inhérents à l'information sous forme numérique mais aussi à l'instabilité grandissante du contexte dans lequel nous vivons.
L’information de représentation peut être concrétisée de la façon suivante dans le cas d’un document textuel rédigé par un service technique :
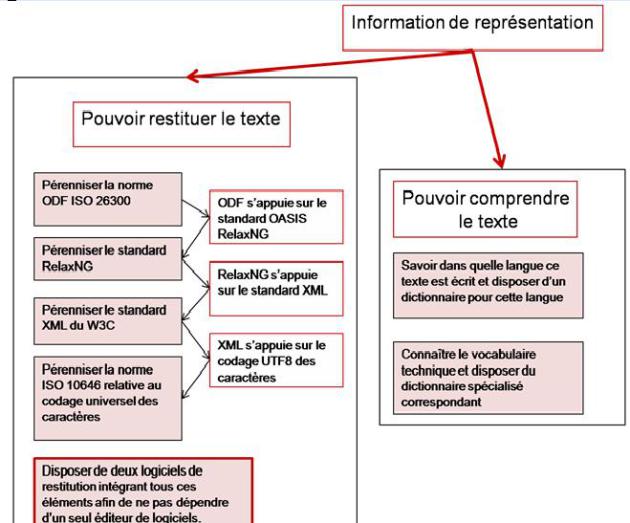
3.3. Information de pérennisation
L'Information de représentation n'est pas suffisante pour que l'Archive assure l'ensemble de ses responsabilités. D'autres informations sont nécessaires, c'est ce qu'on appelle l'Information de pérennisation qui comprend :
L’Information de contexte qui décrit
• les liens entre le Contenu d'information archivé et son environnement,
• les raisons de la création de ce Contenu d’information,
• son rapport avec d’autres objets Contenu d’information. C'est l'information de contexte qui nous permettra de rattacher un objet à un ou à plusieurs ensembles (un fonds, un sous-fonds, un dossier…).
L'Information de provenance qui indique l'origine ou la source du Contenu d'information, qui trace tous les changements intervenus depuis sa création et qui identifie les intervenants de ces changements. Les changements majeurs peuvent être liés à une modification du format des données, modification qui sera dictée pour des raisons d'obsolescence de formats anciens, pour réduire des coûts d'utilisation de formats peu utilisés, ou encore pour répondre aux besoins des utilisateurs dont les besoins imposent un nouveau format.
L'Information d'identification permettant d'affecter un identifiant unique à chaque objet numérique. Cette identification qui existe pour les documents non numériques (ISBN...) prend cependant une importance toute particulière avec le numérique : les identifiants liés à une infrastructure d'ordinateur ou à l'architecture d'un système logiciel – comme c'est souvent le cas pour les adresses des ressources sur Internet – n'ont qu'une faible durée de vie en raison des changements réguliers de ces infrastructures et de ces architectures. L'exigence de disposer d'identifiants qui soient à la fois pérennes et compatibles (sans recouvrement) avec les identifiants utilisés par les institutions partenaires est renforcée par le développement des services « interopérables » permettant de rechercher des documents d'archives simultanément auprès de plusieurs institutions.
L'Information d'intégrité qui consigne les mécanismes de garantie d'intégrité des objets numériques et mémorise la ou les empreintes d'intégrité permettant d'assurer qu'aucun objet numérique archivé n'a subi de modification sans que celle-ci ait été tracée.
A ces catégories d'information, la nouvelle version du modèle OAIS ajoute l'Information de droits d'accès qui définit les régimes de droit attachés aux données (droits d'auteur,...), précise les restrictions et les contrôles d'accès aux objets archivés.
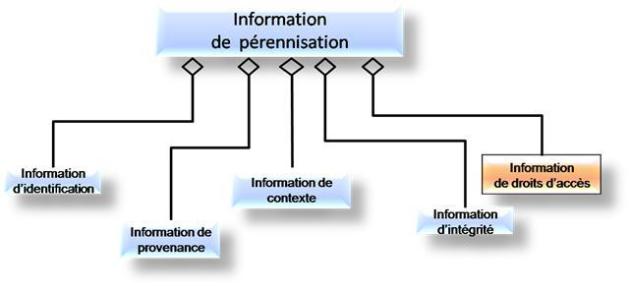
L'Information de droits d'accès est marquée d'une couleur différente car elle fait partie de la nouvelle version du modèle, en cours de normalisation.
3.4. Paquets d'information
Un Paquet d'informations est un conteneur conceptuel au sein duquel le Contenu d'information et l'Information de pérennisation associée à ce contenu sont rassemblés. Le modèle définit trois types de paquets :
• le Paquet d'informations archivé (Archival Information Package, AIP) rassemble un Objet Données (un objet numérique) et l'ensemble des informations nécessaires à la pérennisation des informations contenues dans cet Objet Données, à savoir l'Information de représentation et les cinq composantes de l'Information de Pérennisation (contexte, provenance, identification, intégrité, droits d'accès). L'AIP apparaît ici comme l'objet fondamental manipulé par l'Archive.
• le Paquet d'informations à verser (Submission Information Package, SIP) est celui qui est fourni à l'Archive par le Producteur. Il peut parfois s'avérer nécessaire d'utiliser plusieurs SIP pour obtenir l'ensemble Contenu d'information et Information de Pérennisation, c'est-à-dire un AIP.
• le Paquet d'informations diffusé (Dissemination Information Package, DIP) est fourni par l'Archive aux consommateurs de données.
Cette notion de Paquet permet d'abord de donner une réalité conceptuelle à ce que l'Archive doit effectivement conserver. L'Archive devra en effet s'assurer que, quelle que soit la solution technique retenue, elle dispose effectivement des différentes catégories d'informations numériques constituant les AIP.
L’organisation et les formats retenus pour les Objets Contenu d'information d’un SIP peuvent être différents de ceux retenus pour les AIP. De même, il n’y a aucune raison qu’ils correspondent aux formats et à l’organisation que demandent des utilisateurs. Les Objets Contenu d'information sont donc amenés à être transformés pour répondre à différents besoins. Un DIP pourra donc être créé à partir de plusieurs AIP ou à partir d'une partie seulement d'un AIP.
Dans les mises en œuvre, les paquets peuvent avoir une réalité physique (mais le modèle OAIS ne l'exige pas car il se situe au plan conceptuel). Certaines institutions ont fait le choix de regrouper, au sein d'une même structure physique normalisée, l'ensemble des éléments des SIP, des AIP et parfois des DIP. Nous parlerons, dans la section 9 sur les métadonnées, des normes permettant la création et la gestion de ces Paquets d'information.
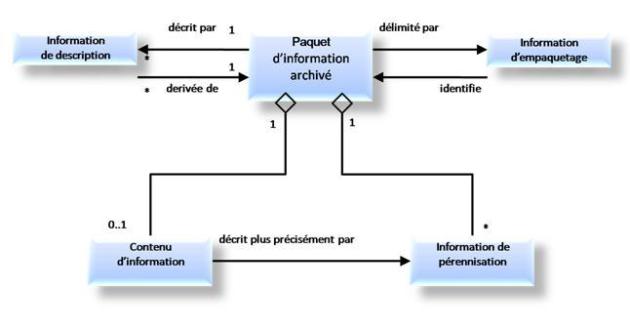
Ce diagramme fait apparaître des objets déjà connus comme le Contenu d'information et l'Information de pérennisation, mais il fait apparaître également de nouvelles catégories d'information.
De quoi s'agit-il ?
• La description des liens réels ou logiques des différents composants d'un Paquet d'informations archivé constitue ce qu'on appelle l'Information d'empaquetage. En pratique, il s'agit de savoir comment nous avons organisé les différentes informations constituant un Paquet et nous devons conserver cette information aussi longtemps qu'elle sera utile : par exemple, la répartition des objets Contenu de données, Information de représentation, Information de pérennisation sur un ensemble de fichiers et de répertoires.
• Toute l'analyse qui précède est fondamentalement dictée par la préoccupation de pérennisation. Si l'on veut que les utilisateurs puissent rechercher, retrouver, évaluer, sélectionner, récupérer, analyser les objets Contenu d'information répondant à leurs besoins, il convient de mettre à disposition de ces utilisateurs une information dite Information de description qui permettra de réaliser les opérations en question. Cette Information de description n'est pas nouvelle, elle est extraite des informations précédemment décrites, elle en constitue le sous-ensemble utile aux processus d'interaction avec les utilisateurs. L'Information de description peut être reconstruite, régénérée, recalculée au fil du temps pour répondre à des besoins nouveaux des utilisateurs. Elle correspond par exemple à ce qui sera appelé « métadonnées descriptives ». Plus largement, toute information extraite de l'AIP et qui jouera un rôle dans le processus de recherche d'informations sera une information de description.




