Records in Contexts (RIC) : de l'abstrait au concret

N° 28
(16 juillet 2024)
Article de Anne-Marie Bruleaux,
Introduction
Pendant près d’une décennie, RIC n’a été qu’un objet abstrait, ou du moins purement théorique, sauf pour les membres d’EGAD (Expert Group on Archival Description) qui travaillèrent sans relâche à en faire l’avenir de la description archivistique. C’est seulement depuis environ trois ans que des projets de mise en œuvre ont vu le jour et se sont développés dans plusieurs institutions de par le monde, notamment dans des pays francophones. Offrir à leurs promoteurs l’occasion de présenter leur expérience était justement l’objectif de la journée d’étude internationale sur les premières implémentations de RIC, qui a eu lieu le 15 novembre 2023 aux Archives nationales de France.
Qu'est-ce que Records in Contexts (RIC) ?
Avant d’évoquer les présentations de cette journée, il n’est pas inutile de rappeler brièvement ce qu’est RIC. Tout d’abord c’est le sigle de l’expression anglophone « Records in Contexts » qui résume à elle seule toute la philosophie du projet : créer, en fusionnant, articulant et complétant les quatre normes internationales existantes, un modèle mettant le contexte de production, de conservation et d’utilisation des archives au cœur de la description archivistique. La première des quatre normes rédigées et publiées par le Conseil international des Archives fut en 1994 la norme générale et internationale de description archivistique (ISAD/G) pour la description à plusieurs niveaux des unités documentaires, bientôt suivie par la norme internationale sur les notices d’autorité utilisées pour les archives relatives aux collectivités, aux personnes ou aux familles (ISAAR/CPF)) en 1995. Force est de constater que ces deux premières normes, respectivement mises à jour en 1999 et 2004, connurent plus de succès que les deux suivantes : la norme internationale pour la description des fonctions (ISDF) et la norme internationale pour la description des institutions de conservation des archives (ISDIAH), toutes deux publiées en 2008.
RIC émane du groupe d’experts EGAD mandaté en 2012 par le Conseil international des archives (ICA) pour construire un cadre de référence unique et global de description des archives. Le travail d’EGAD, engagé en 2013, devait produire deux livrables : un modèle conceptuel (RIC-CM) et une ontologie (RIC-O). Les premières versions en ont été publiées et soumises à commentaires en 2016 (RIC-CM 0.1 et RIC-O 0.1). Un deuxième appel à commentaires a eu lieu en 2021 sur les versions 0.2. Les versions stables et complètes (1.0) ont été publiées à la fin de l’année 2023. A ces deux livrables, s’ajoute une introduction à la description archivistique selon le modèle, intitulée Fondations de la description archivistique (RIC-FAD). Enfin, le groupe EGAD travaille à un manuel d’application ((RIC-AG) qui doit être publié à la fin 2024.
Records in Contexts est donc un ensemble qui, à terme, sera composé des quatre éléments suivants :
RIC-FAD (Foundations of Archival Description - Fondations de la description archivistique) : c’est une brève introduction aux principes et aux buts de la description archivistique. Ce texte replace RIC dans le contexte de l’histoire de l’élaboration par l’ICA des normes de description. Il est téléchargeable, en anglais, à l’adresse suivante : https://www.ica.org/app/uploads/2023/12/RiC-FAD-1.0.pdf
RIC-CM (Conceptual Model - Modèle conceptuel) : c’est un modèle conceptuel de haut niveau pour la description intellectuelle des archives. Sa portée est très large et inclut autant les documents d’activités (records) que les archives définitives. Il est aussi adapté aux archives sur supports traditionnels qu’aux archives numériques. RIC-CM identifie les entités (objets d’intérêt), leurs caractéristiques intrinsèques (attributs) et les relations qui sont susceptibles d’exister entre ces entités. Le modèle compte 19 entités (dont record ressource, agent, instanciation, activity), 42 attributs et 85 relations.
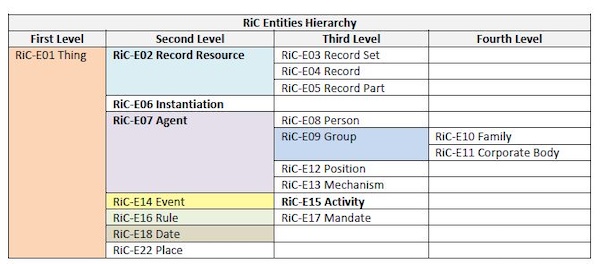
Fig.1-Hiérarchie des entités de RIC (RIC-CM, p.17)
Alors que l’ISAD/G donnait des règles de description pour la rédaction d’un instrument de recherche, RIC-CM s’intéresse à l’objet à décrire en tant que contenu intellectuel, indépendamment de son contenant, de sa réalité physique, que le modèle considère comme une instanciation. RIC offre la possibilité de passer d’une description à niveaux normée par l’ISAD/G à une description multidimensionnelle et multicontextuelle, d’une hiérarchie unique (celle de nos instruments de recherche) à un graphe ou réseau d’entités liées. Pour bien comprendre ce qu’est RIC-CM, on peut télécharger le modèle en anglais à l’adresse suivante :https://www.ica.org/app/uploads/2023/12/RiC-CM-1.0.pdf
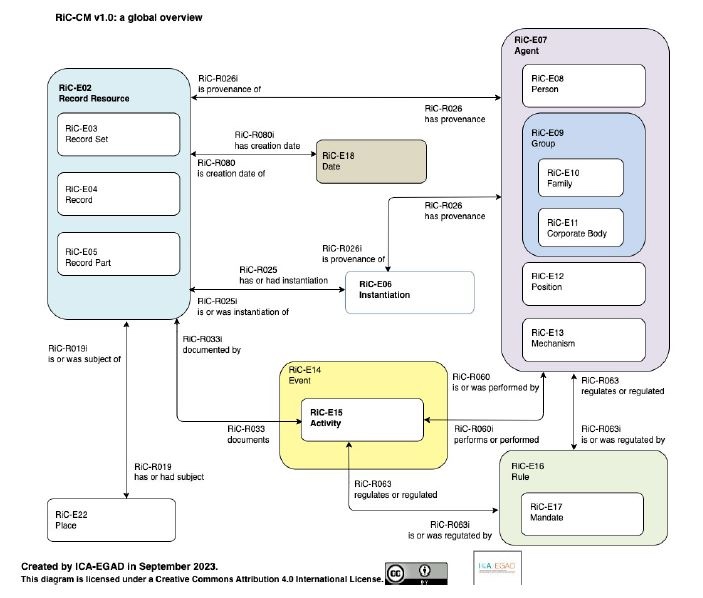
Fig.2-Vue globale de RIC-CM (RIC-CM, p.18)
RIC-O (Ontology - ontologie) : c’est la transposition technique de RiC-CM dans le langage OWL (Web Ontologie Language), qui offre à la communauté archivistique, avec un vocabulaire générique métier, la possibilité de produire des métadonnées archivistiques sous la forme de données liées en langage RDF (Resource Description Framework).
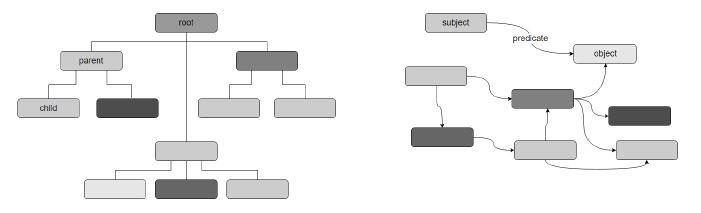
Fig.3-À gauche, représentation des données en une structure hiérarchique (langage XML) : à droite, représentation des données en triplets (langage RDF) aboutissant à un graphe de connaissances (RIC-CM, p.6)
Autrement dit, RIC-O est en fait la grammaire qui permet de mettre en pratique le modèle conceptuel RIC-CM dans le web sémantique. Pour ce faire, cette ontologie définit 105 classes (ou catégories), 61 data properties et 400 Object properties. Pour simplifier, les classes correspondent aux entités de RIC-CM, les data properties aux attributs et les objects properties aux relations ; mais il y des exceptions, certaines relations et certains attributs pouvant être des classes. Dans sa forme OWL, l’ontologie n’est accessible qu’aux machines. Pour mieux comprendre de quoi il s’agit, il est possible de consulter une version HTML, donc lisible par les humains, sur le lien suivant : https://www.ica.org/standards/RiC/RiC-O_1-0-1.html
Il faut remarquer aussi que dans cette version tous les noms (labels) d’éléments sont donnés en anglais, en français et en espagnol. Par ailleurs, pour chacun est indiqué ce à quoi il correspond dans RIC-CM qui comporte des exemples concrets d'utilisation. Il est important aussi d’insister sur la flexibilité de cette ontologie, qui par la polyhiérarchie des classes et des properties s’adapte particulièrement bien à la description archivistique, flexible par nature avec sa granularité plus ou moins fine. De plus, RIC-O est extensible : les institutions peuvent librement ajouter des sous-classes ou des sous-propriétés selon leurs besoins, notamment pour intégrer des vocabulaires contrôlés au format SKOS.

Fig.4-Thesaurus des types de documents des Archives nationales de France, converti en RDF, conforme à SKOS et RIC-O 0.2 (vue partielle). L'intégralité du fichier est consultable à cette adresse.
RIC-AG (Application Guidelines - Directives d’application) : c’est un manuel en cours de rédaction qui fournira aux praticiens et aux développeurs de logiciels des conseils et des exemples concrets pour les aider à mettre en œuvre RiC-CM et RiC-O dans les systèmes de gestion des documents d’activité et des archives.
Records in Contexts : une révolution de la pratique ?
Avant d’aborder les premières réalisations concrètes, il est important de comprendre ce que va changer RIC pour les archivistes et leurs publics. Tout d’abord, il faut rassurer les professionnels : RIC étant un prolongement des quatre normes existantes, les descriptions archivistiques réalisées jusqu’à présent ne vont pas être anéanties. Autrement dit, tous les archivistes qui ont rédigé des instruments de recherche en respectant l’ISAD/G et qui ont utilisé XML/EAD et XML/EAC pour les encoder ne vont pas perdre le fruit de leur travail. De ce point de vue, il faut souligner que RIC-O est immédiatement utilisable. Certes, il y aura des procédures à mettre en œuvre pour transférer des descriptions encodées en EAD et EAC vers RIC-O, mais des outils de conversion existent déjà. Par ailleurs, RIC-CM,qui est désormais le modèle recommandé par le Conseil international des archives, ne va pas obliger les archivistes à bouleverser leurs pratiques actuelles. Il est en effet possible d’utiliser l’EAD 2002 et l’EAC-CPF 1.0, ou surtout 2.0, pour produire des données s'articulant étroitement avec RIC-CM. Cela implique cependant d’en faire une application rigoureuse ou de l’obtenir des éditeurs de progiciels pour produire des métadonnées structurées de qualité. Ainsi, par exemple, il convient de toujours renseigner l’attribut <level>, de traiter les niveaux intermédiaires comme des descriptionsà part entière avec cotes et dates extrêmes, et non comme des titres de partie. Il faut aussi être particulièrement vigilant à l’indexation. En France, il convient désormais de se référer au Guide d’indexation des archives à l’heure du web, publié par le Service interministériel des archives de France. Il est important aussi de disposer d’URI (Uniform Ressource Identifier) pour chaque niveau de description et pour toute entité d’indexation. Enfin, il faut continuer à rédiger des notices de producteurs d’archives, en les liant aux descriptions de leurs fonds, comme cela s’est fait, quasiment depuis l’origine de l’encodage, aux Archives de la Ville de Genève, ou dans d’autres institutions, par exemple aux Archives nationales de France avec l’ancienne base de donnée Etanot (répertoire numérique des archives notariales et notices descriptives des notaires), intégrée aujourd’hui à la salle de lecture virtuelle (https://www.siv.archives-nationales.culture.gouv.fr/siv/cms/content/fonds.action?uuid=12b&template=pog/pogLevel2&preview=false). Mais plusieurs de ces recommandations ne sont pas nouvelles. Il est aussi prévu de faire évoluer le schéma EAD : une version EAD4, plus conforme à RIC, est annoncée pour 2025.
Si le travail de l’archiviste ne s’en trouve pas fondamentalement bouleversé, RIC ouvre néanmoins des perspectives de changements importants. Tout d’abord il sera possible d’obtenir une description archivistique beaucoup plus riche, plus précise, plus nuancée. Quel archiviste, tentant de rendre compte de la complexité des archives et de leurs contextes, n’a pas ressenti un jour une profonde frustration devant l’imperfection des outils qu’il avait à sa disposition ? Souvent, dans les inventaires sur papier, on ajoutait des notes de bas de page, qu’il était ensuite bien difficile de prendre en compte au moment de la rétroconversion pour l’affichage en ligne. Quel archiviste n’a pas perçu l’insuffisance de l’image bidimensionnelle que renvoie un instrument de recherches conforme à l’ISAD/G, elle-même héritière d’une longue tradition archivistique ? Nos instruments de recherches actuels en effet décrivent les fonds comme des univers clos et ne prennent en compte que le contexte documentaire direct, c’est-à-dire l’agrégation d’archives dans un ordre hiérarchique (fonds, sous-fonds, série, sous-série, dossier, pièce) et séquentiel (à un même niveau toutes les séries, puis toutes les sous-séries, etc.), ainsi que le producteur. Comme seule ouverture vers des ressources extérieures, ils n'offrent que la bibliographie et, pour les fonds d'archives, les sources complémentaires, encodées en EAD par les balises <relatedmaterial> et <separatedmaterial> selon les cas. RIC-CM, conçu comme un modèle entités-relations, doit permettre de mieux répondre aux besoins d’une description complexe et multidimensionnelle, d’entrer dans la multiplicité des contextes de production, de transmission et de gestion.
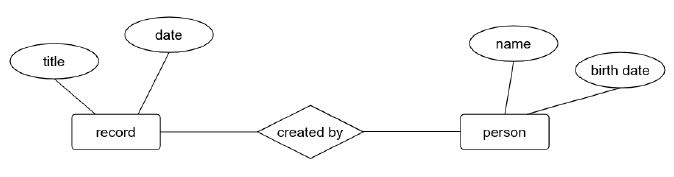
Fig.5-Représentation basique d'un modèle Entités-relations, avec entités (record, person), attributs (title, date, name, birthdate) et relation (created by), (RIC-CM, p.4)
Cette multidimensionnalité potentielle est particulièrement intéressante à une époque où la notion de fonds a tendance à se dissoudre dans le travail collaboratif, fruit d’une multiplicité simultanée de producteurs, et où la notion de producteur elle-même tend à laisser la place à celle de grande fonction organique, voire de projet. Du reste, RIC modernise aussi la notion de producteur, en considérant sous l’entité Agent, non seulement comme jusqu’à présent une personne ou un groupe famille, collectivité), mais aussi un Mechanism, générateur d’archives en autonomie ou semi-autonomie selon des règles définies par une personne ou un groupe : il peut s’agir, par exemple, d’un logiciel, d’un système d’information, d’une sonde océanique, d’un astromobile ou d’une intelligence artificielle. Le modèle ajoute aussi Position (poste occupé), qui fait de la fonction « Directeur » ou « Président de la République », par exemple, un producteur d’archives, indépendamment de la personne qui occupe le poste.
Ainsi Florence Clavaud nous invite à « envisager ces couches de contextes interconnectés comme des points de vue différents : la provenance organique et fonctionnelle, le contexte documentaire (les relations entre documents eux-mêmes), et bien d’autres (par ex. les facettes que la diplomatique distingue, comme l’auteur du document, son destinataire ; celles que l’indexation classique des IR [instruments de recherche] considère, comme les sujets des documents, etc.). »
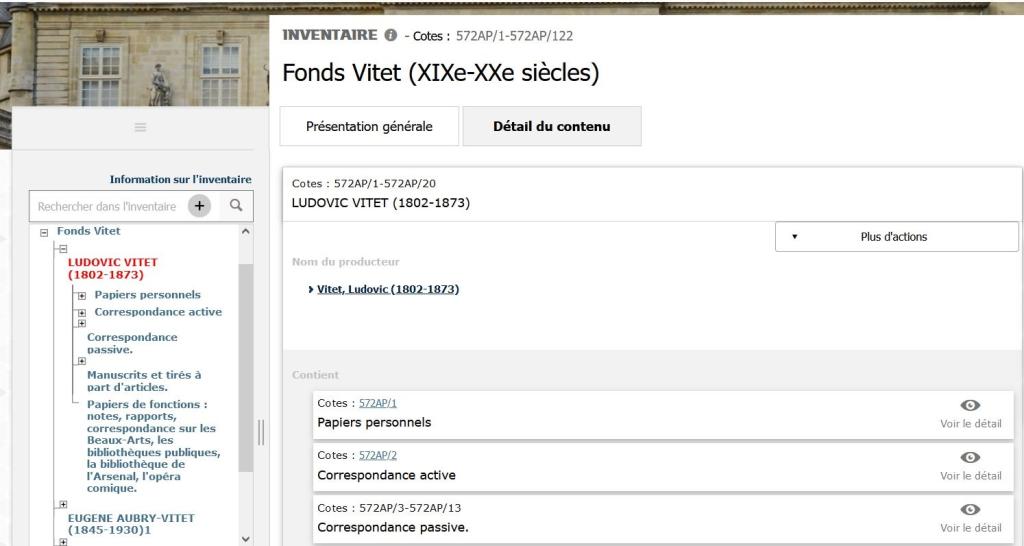
Fig.6- Inventaire du fonds Vitet encodé en XML/EAD : vue HTML, dans la salle de lecture virtuelle des Archives nationales de France (vue partielle). Consultable à cette adresse. L'inventaire est exportable en XML/EAD.
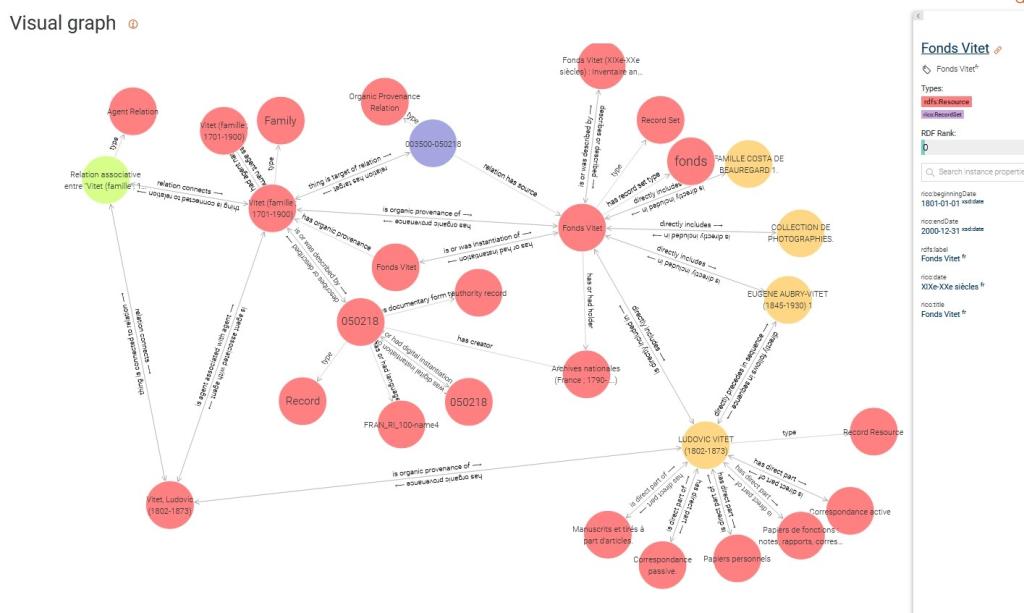
Fig.7- Inventaire du fonds Vitet encodé en RDF selon RIC-O : graphe de connaissances. Consultable à cette adresse.
La multiplicité des entités de contexte permet de mettre à disposition de l’usager une multitude de points d’accès qu’il lui est possible d’interroger et de croiser selon ses besoins. La description des entités de contexte existe souvent déjà sous forme de référentiels ou vocabulaires contrôlés – actuellement utilisés notamment pour le contenu de la balise EAD <controlaccess>. Par ailleurs, elles font aussi l’objet de descriptions dans d’autres univers professionnels et peuvent constituer des nœuds de liage avec les métadonnées d’autres institutions, ce qui facilite l’interopérabilité entre les jeux de métadonnées et leur enrichissement mutuel. Il était déjà possible avec EAD et EAC de faire le lien par exemple entre la description d’un producteur et la notice d’autorité de la Bibliothèque nationale de France. Avec RIC, cette possibilité est considérablement augmentée et permet de constituer un véritable réseau, un vaste graphe de connaissances.
Pour illustrer brièvement les potentialités de RIC-CM, et de RIC-O qui propose une déclinaison encore plus riche du modèle, il suffit de prendre un exemple concret : avec XML/EAD, si l’on veut indiquer la langue dans laquelle sont écrits les documents d’une unité archivistique, il faut utiliser l’élément <langmaterial>, puis l’élément <language> pour spécifier la ou les langues, en ajoutant éventuellement des informations en langage naturel entre les balises. RIC permet de préciser si tous les documents décrits dans une unité sont dans une langue, ou seulement une partie, ou la majorité. Ce traitement sémantique très fin offre des possibilités de recherches différentes : par exemple, il devient envisageable de faire ce type de requête dans un fonds multilingue comprenant des documents en français, en chinois et en russe : quels sont les dossiers où la majorité des documents sont en français ? Quels sont les dossiers qui comprennent une partie de documents en chinois ? Y a-t-il des dossiers dont tous les documents sont en russe ?
Cet exemple montre que RIC va engendrer des changements importants pour l’utilisateur en rendant les descriptions archivistiques plus exploitables, en élargissant le champ des possibles par une toute nouvelle façon de consulter les métadonnées archivistiques et leurs multiples contextes. C’est ce que montrent les expérimentations actuellement menées en France et à l’étranger.
Les exemples français d'utilisation de RIC
Les premiers essais d’interfaces construites pour naviguer dans les métadonnées archivistiques produites avec RIC-O ont été les graphes de connaissance qui affichent sous forme graphique les réseaux de données. Ainsi, le prototype PIAAF (Pilote d’interopérabilité pour les Autorités Archivistiques françaises) consultable à l’adresse suivante https://piaaf.demo.logilab.fr/, a été construit en collaboration par le Service interministériel des archives de France, les Archives nationales de France, la Bibliothèque nationale de France et la société Logilab. S’il permet de rendre compte de la complexité des données et de la manière de rebondir d’un jeu de données à un autre, en les situant aussi dans la durée historique, il rend assez perplexe sur l’efficacité d’une telle représentation pour accéder à l’information que cherche l’utilisateur, le mettant devant une multiplicité de chemins qui, certes, reflète bien la complexité des archives, mais peut être ressentie comme déroutante.
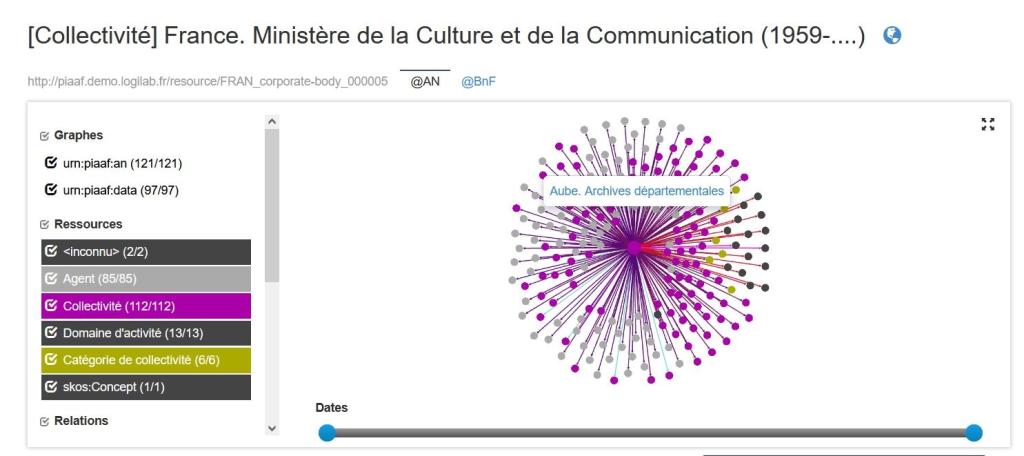
Fig.8-Exemple de graphe dans le PIAAF
Les graphes de connaissances constitués avec RIC-O peuvent aussi être interrogés en construisant des requêtes avec le langage SPARQL (Simple Protocol And RDF Query Language). Dans le démonstrateur PIAAF, il est possible de construire des requêtes, et des exemples sont fournis (https://piaaf.demo.logilab.fr/sparql). Mais peu nombreux sont les utilisateurs qui en maîtrisent la syntaxe. C’est pourquoi les Archives nationales de France ont mis en place, grâce à l’outil Sparnatural, deux interfaces plus intuitives qui permettent de tester les potentialités de recherches dans une partie des métadonnées décrivant les archives des notaires de Paris. Les deux démonstrateurs peuvent être testés à l’adresse suivante : https://sparna-git.github.io/sparnatural-demonstrateur-an/index.html. On peut, par exemple, pour les fonds dont les descriptions ont été transposées en RDF selon RIC-O - soit environ un tiers -, demander la liste des actes notariés datant de 1848 avec leur cote, ce qui est actuellement impossible à obtenir avec le moteur de recherche utilisé dans la Salle de lecture virtuelle des Archives nationales.
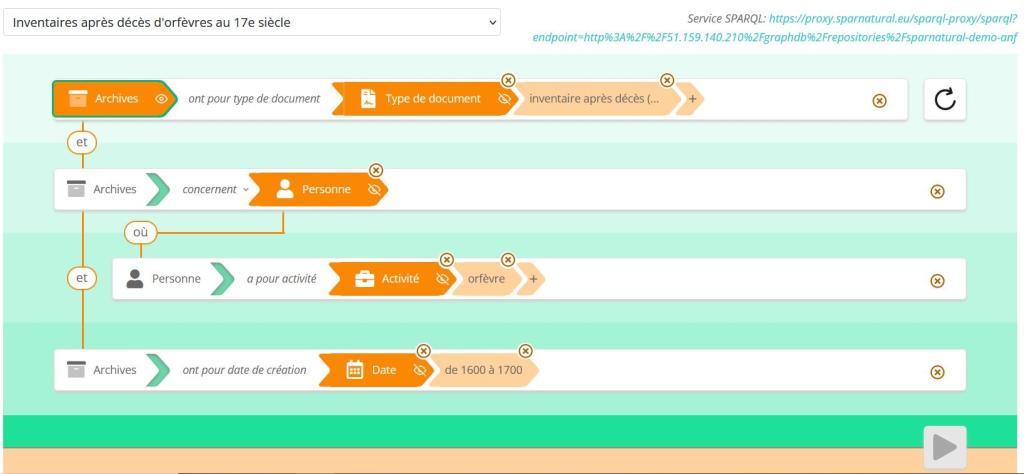
Fig.9- Archives nationales de France : exemple de requête construite avec SPARNATURAL
Cette expérience n’est qu’un pâle reflet de l’immense chantier engagé depuis 2017 aux Archives nationales de France pour sémantiser leur énorme réservoir de métadonnées descriptives dont l’hétérogénéité des formats et la dissémination en silos ne permet actuellement pas l’interconnexion. Cette institution a aussi généré, au fil des ans, 20 000 notices d’agents (producteurs ou autres acteurs), 60 000 entrées décrivant des lieux et 20 référentiels d’indexation, qu’il convient de valoriser et de rendre facilement utilisables en les standardisant et en les alignant, autant entre eux qu’avec des référentiels d’autres institutions.
Dans le sillage des Archives nationales de France, le portail FranceArchives, agrégateur des archives françaises, s’est lancé dans un ambitieux projet de conversion en RDF des métadonnées d’une ampleur exceptionnelle. FranceArchives en chiffres, c’étaient, au 9 novembre 2023, 138 fournisseurs de contenus (dont une grande partie des Archives départementales), 83 301 instruments de recherche, plus de 21 millions d’unités de description, 16 000 notices encodées en EAC, plus de 8 millions sept cent mille noms dans la base de données nominative, 5 000 pages de contenu éditorial (aides à la recherche, expositions virtuelles, pages d’histoire, publications, valorisation des collections et activités, ressources professionnelles). L’ensemble des métadonnées converties représentait alors 400 millions de triplets RDF, ce qui constitue un véritable défi pour une exploitation avec les outils actuellement disponibles. Les référentiels de FranceArchives sont par ailleurs en interconnexion avec ceux de Wikidata et Data.bnf pour les noms d’agents et Geoname pour les noms de lieux. Pallier la qualité technique inégale des données apportées par les fournisseurs de contenu fait aussi partie des défis à relever. C’est donc un immense chantier qui se poursuit aujourd’hui, une conversion en RDF des métadonnées intégrées dans le portail étant réalisée tous les 6 mois. Le résultat le plus tangible de ce travail est l’interface d’interrogation en SPARQL construite avec Sparnatural proposée aujourd’hui par le portail, à côté de son moteur de recherche qui reste disponible. Cette interface peut être essayée à l’adresse suivante : https://francearchives.gouv.fr/fr/requeteurnaturel.
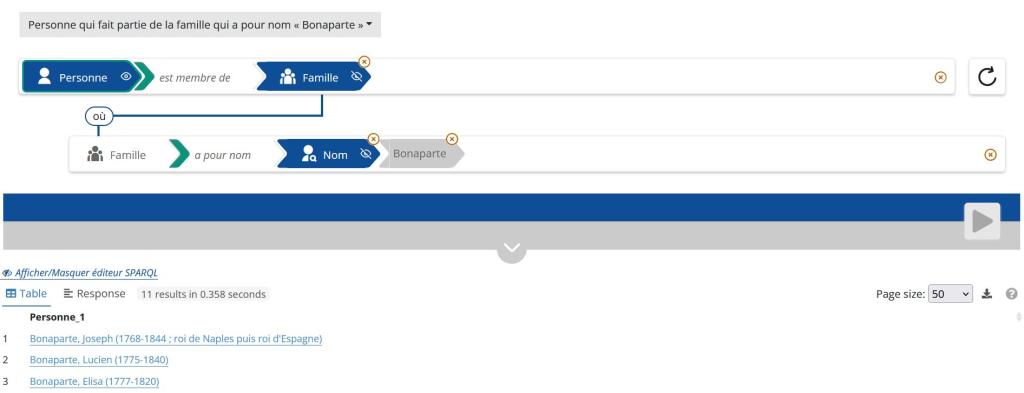
Fig.10-Portail FranceArchives : exemple de requête construite avec SPARNATURAL sur la famille Bonaparte (vue partielle)

Fig.11-Portail FranceArchives : notice d'autorité de Joseph Bonaparte, première occurrence dans les résultats de la requête précédente, avec les personnes et institutions liées d'après Wikidata
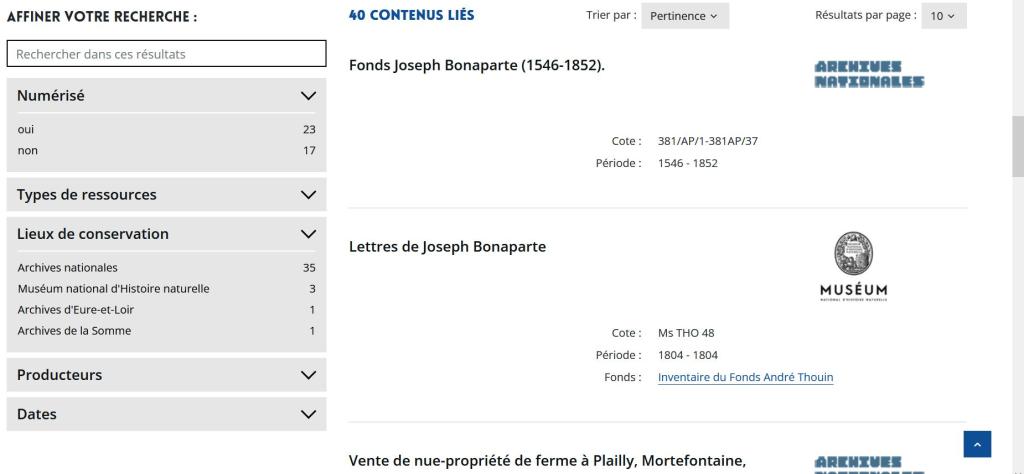
Fig.12-Portail FranceArchives : à la suite de la notice d'autorité de Joseph Bonaparte, liste des contenus liés (vue partielle)
Les exemples d'utilisation de RIC dans la Francophonie
Outre ces expériences françaises, plusieurs autres réalisations ont été présentées, lors de la journée du 15 novembre 2023, dans des Archives nationales (Norvège, Suède, Singapour, Liechtenstein) et dans d’autres institutions (Archives de la Ville d’Amsterdam, Archives de l’État de Malte). Pour ne s’en tenir qu’au monde francophone, il convient de remarquer le dynamisme de la Suisse : dès la publication de la version stable de RIC, les Archives cantonales vaudoises se sont lancées dans l’élaboration d’un modèle de données conforme à RIC et couvrant tout le cycle de vie des archives, depuis leur versement jusqu’à leur diffusion ; elles se sont appuyées sur l’existant – les outils actuels de description et de gestion électronique des documents -, mais ont analysé aussi les nouvelles possibilités, notamment, pour la description, l’ajout de nouveaux types de contextes et les liens vers d’autres plateformes (archives, Wikidata, bibliothèques, etc.).
Dans d’autres institutions suisses, des outils de production sont déjà mis en œuvre : ainsi l’agrégateur national de ressources audiovisuelles Memobase, mis en place par l’association Memoriav, a fait migrer ses métadonnées en conformité avec RIC depuis deux ans. Outre son accès classique, cela lui permet de proposer un accès Linked Open Data plus expert pour une partie de ses données à l’adresse suivante : https://api.memobase.ch/
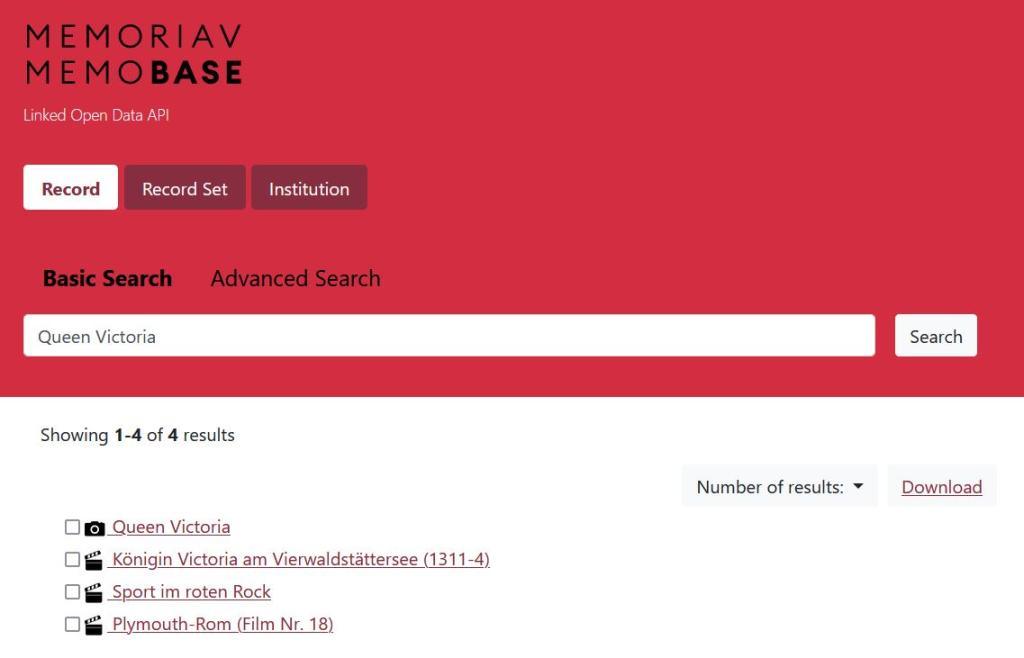
Fig.13- Exemple de requête dans le point d'accès SPARQL de Mémobase
Les Archives fédérales suisses gèrent le portail LINDAS (Linked Data Service), avec un point d’accès SPARQL permettant d’interroger notamment leurs instruments de recherche convertis selon RIC-O ; à partir des jeux de données présents sur LINDAS, il est possible d’utiliser une plateforme web de visualisation des données, à l’adresse suivante : https://visualize.admin.ch/fr
La fondation SAPA (Swiss Archives of the Performing Arts) qui collecte, documente, archive et diffuse des œuvres du domaine des arts du spectacles (danse, théâtre, performance) produites en Suisse ou liées à la Suisse, a migré en 2021 ses métadonnées en RDF selon RIC-O et a mis en ligne un nouveau portail de ses collections : https://www.performing-arts.ch/
Des outils pour RIC
Parallèlement aux réalisations, et ayant d’ailleurs permis une partie d’entre elles, des outils ont aussi vu le jour. Le Composant Javascript Sparnatural a déjà été évoqué ci-dessus : il permet de construire visuellement des requêtes SPARQL pour naviguer dans un graphe de connaissances. Le convertisseur de données RIC-O Converter a été développé par les Archives nationales de France avec la société SPARNA. Il permet de convertir des métadonnées encodées en XML/EAD 2002 et XML/EAC-CPF, avec toutefois quelques limites : il ne couvre pas l’intégralité des éléments EAD et EAC, dans la mesure où il ne traite que ceux utilisés par les Archives nationales de France. Il ne traite pas non plus les données générées au format SEDA utilisé lors des versements d’archives électroniques. Mais étant un logiciel libre et mis à disposition de tous dans GitHub, il peut être amélioré et adapté aux besoins d’autres institutions. Il faut enfin signaler que la société suisse Docuteam propose désormais un système d’information archivistique basé sur RIC, Docuteam Context. Cette grande avancée devrait inciter les autres fournisseurs de progiciels, en France ou dans d’autres pays francophones, à intégrer RIC dans leur offre.
Lors de la journée du 15 novembre 2023 a enfin été présenté un autre outil, cette fois à destination des chercheurs, qui s’appuie aussi sur RIC : il s’agit de la plateforme HEURIST qui permet de créer et gérer des bases de données en sciences humaines et sociales. La présentation en est faite à l’adresse suivante : https://ptm.huma-num.fr/outil-heurist-une-base-de-donnees-generique-pou…;
Sans être de nature à angoisser les archivistes, les changements induits par RIC pour la description archivistique et les possibilités d’interrogation par l’utilisateur sont importants et très prometteurs, comme en témoignent les premières mises en œuvre à travers le monde. Par ailleurs, les connexions avec les musées et les bibliothèques dotés aussi de modèles conceptuels et d’ontologies correspondantes (respectivement CIDOC-CRM et IFLA LRM) devraient être facilitées, d’autant que le groupe EGAD se donne désormais pour mission de développer les passerelles entre RIC et ces autres modèles.
Vers un mode de collaboration inédit entre archivistes et chercheurs...
Un autre changement de taille se profile : un mode de collaboration inédit entre archivistes et chercheurs. C’est ce que démontrent plusieurs projets de recherche en cours en France. Le projet ORESM (Œuvres et Référentiels des Étudiants, Suppôts et Maîtres de l’université de Paris au Moyen Âge), initié en 2019 par la Bibliothèque interuniversitaire de la Sorbonne, avec le laboratoire de médiévistique occidentale de Paris (LaMOP), et les Archives nationales de France a pour objectifs d’une part, de mieux comprendre la composition et l’histoire du fonds d’archives de l’université de Paris, aujourd’hui fragmenté ; d’autre part, d’étudier le réseau de personnes et d’institutions formant l’université ou liées à elle au Moyen Age. Après une action de préfiguration sur un petit nombre de données sémantisées avec RIC-O, qui démontrait la faisabilité et l’intérêt du projet, un stagiaire du master 2 « Technologies numériques appliquées à l'histoire » de l’École nationale des chartes a eu pour mission d’étendre l’expérimentation à l’ensemble des données disponibles, de démontrer les avantages de la sémantisation, de commencer à exploiter les données en un graphe de connaissances, de réfléchir aux besoins des utilisateurs. En novembre 2023, 1441 pièces étaient décrites très finement pour répondre aux besoins des chercheurs : personnes liées au document et rôles de ces personnes, typologie et forme des documents, tradition et état de la pièce décrite. Pour atteindre cette précision dans la description, il a fallu ajouter une extension à RIC-O. Pour les archivistes, ce projet a un grand intérêt, car il sera possible d’enrichir les instruments de recherche des Archives nationales en y transférant ces descriptions très fines.
D’autres projets de recherche menés en collaboration avec les Archives nationales de France font aussi appel à la description conforme à RIC-O pour la constitution et l’exploitation de bases de données, tels ALEGORIA (structurAtion et vaLorisation du patrimoinE géoGraphique icOnogRaphIquedémAtérialisé) qui traite 90 000 photographies des Archives nationales, de l’IGN (Institut géographique national) et du musée Niepce ; ou SoDuCo (Social Dynamics in Urban Context) qui a pour objectif d’étudier l’évolution de la structure spatiale urbaine en relation avec les pratiques sociales et professionnelles de la population, à travers la reconstitution de l’évolution de Paris de 1789 à 1950.
Conclusion
En conclusion, le modèle Records in Contexts ouvre une nouvelle ère pour les archivistes et les usagers des archives, ou même pour le public plus général des internautes qui entre d’ores et déjà dans le web des données liées. Certes, les modes d’interrogation avec les requêtes SPARQL peuvent paraître très techniques et peu accessibles à un public non expert, même avec l’habillage d’un outil comme Sparnatural. De ce point de vue, il y a encore de grands progrès à faire pour permettre au public de profiter pleinement des opportunités que représente cette nouvelle façon d’utiliser les métadonnées.
Références utilisées :
FranceArchives. Records in Contexts : un nouveau modèle de description archivistique. Consulté le 12 juin 2024 à l’adresse https://francearchives.gouv.fr/fr/article/334841641
FranceArchives, Effectuer des requêtes SPARQL guidées avec l'outil Sparnatural. Consulté le 26 juin 2024 à l'adresse https://francearchives.gouv.fr/fr/article/756183860
Groupe d’experts sur la description archivistique – EGAD. Records in Contexts (RIC). Consulté le 12 juin 2024 à l’adresse https://www.ica.org/fr/reseau-ica/groupes-dexperts/egad/records-in-contexts-ric/
Krause-Bilvin, Jan. Développement du modèle de données des Archives cantonales vaudoises et focus sur l’interopérabilité, Arbido, 2023/3. consulté le 18 juin 2024 à l’adresse https://arbido.ch/fr/edition-article/2023/archives-in-contexts/developpement-du-modele-de-donnees-des-archives-cantonales-vaudoises-et-focus-sur-linteroperabilite
Le labo des archives (2020, 14 février). Les métadonnées archivistiques en transition vers des graphes de données : 1- les présentations de la journée du 28 janvier 2020. Archives nationales, carnet de recherche. Consulté le 18 juin 2024, à l’adresse https://doi.org/10.58079/qnw7
Le labo des archives (2021, 8 juillet). Les métadonnées archivistiques en transition vers des graphes de données : 2 – point d’actualité et précisions sur Records in Contexts. Archives nationales, carnet de recherche. Consulté le 18 juin 2024, à l’adresse https://doi.org/10.58079/qnwj
Les premières implémentations de Records in Contexts. Journée d’étude internationale du 15 novembre 2023, Archives nationales de France. Enregistrement vidéo disponible à l’adresse https://www.dailymotion.com/playlist/x86ajs
Webinaires des 11 et 20 juin 2024 sur RIC.1.0, animés par Florence Clavaud, membre exécutif d’ICA-EGAD, responsable du Lab des Archives nationales de France, responsable de l’équipe de développement de RIC-O. Prochainement disponible sur Dailymotion, playlist des Archives nationales de France Cycle de webinaires sur Records in Contexts à l’adresse https://www.dailymotion.com/playlist/x7cdgp
Nous remercions infiniment Madame Anne-Marie Bruleaux de sa précieuse collaboration.
 Suivez-nous sur LinkedIn
Suivez-nous sur LinkedIn{kind=link}